AI being the buzz, lots of people are trying to get their feet wet with a basic understanding of AI, how it works, and how it can be useful to them. There are two aspects to understanding AI—learning the theory behind it in detail, or learning how it can be used in your day-to-day life. For most people, the latter will be sufficient; they do not need to understand the underlying theory to get going. However, for someone trying to build a career around AI or aiming to enter the field of research, keeping the basics clear is of utmost importance.
Being an ML software engineer, sometimes it gets overwhelming to stay updated with what’s going on while keeping my fundamental understanding clear. Whenever I read a new research paper after a certain gap, it feels like I’m missing out on core comprehension because of forgotten foundational theory.
So, I am writing this guide for myself and others who are in the same boat, to quickly ramp up with AI basics. It contains resources, topics, and essential notes from my journey.
Prerequisites
Obviously, you will need to have a basic ML understanding beforehand to ride the wave. By basic, I mean you should have knowledge of Mathematics (Calculus, Probability, and Linear Algebra) and some knowledge of ML—how a basic ML model works, including Linear Regression, Neural Networks, and Loss Function optimization. Highly Recommended: Deep Learning Specialization by Andrew Ng
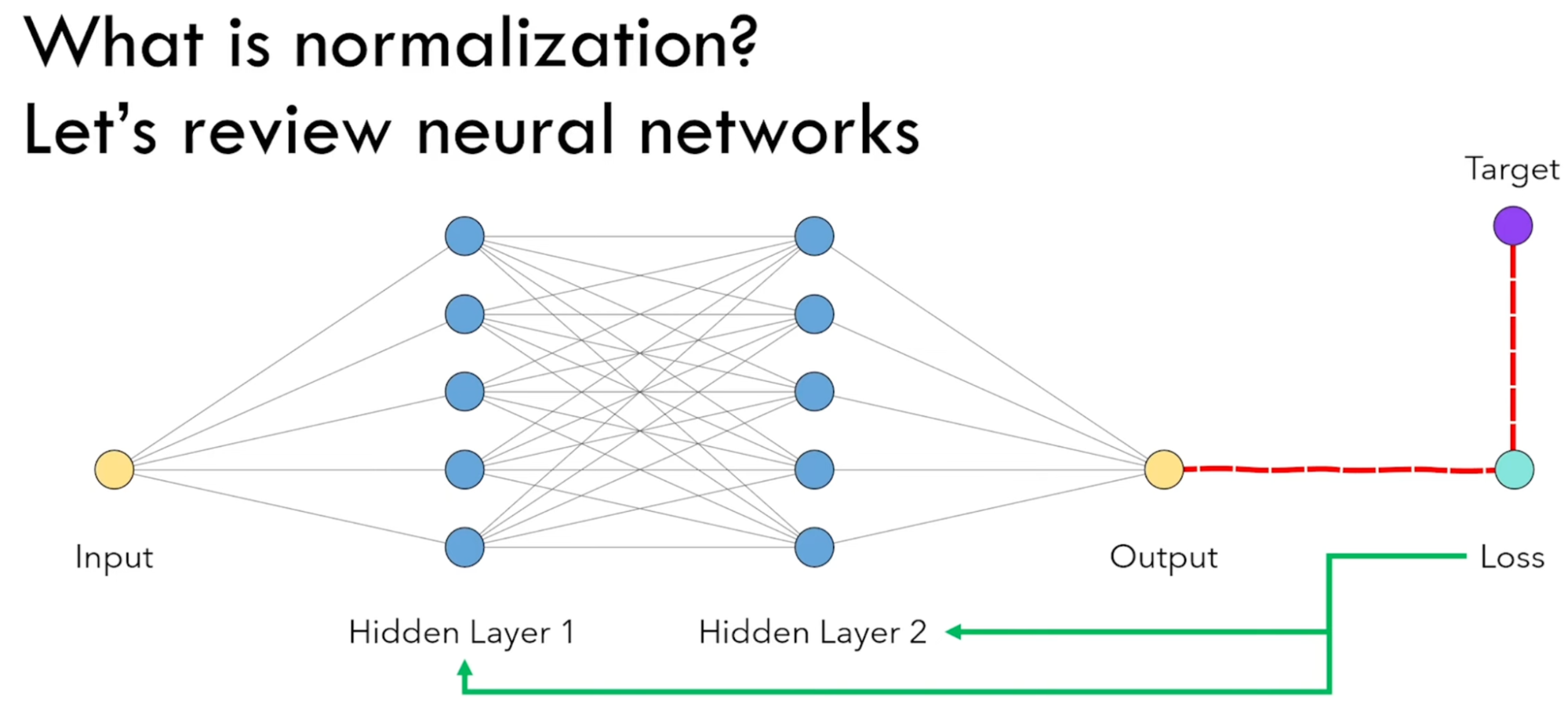
Let’s Get Started
Stating the obvious just for bookkeeping, the anchor point in the Generative AI stage was this seminal paper: Attention Is All You Need! You should remember all its authors—Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. (It’s interesting to follow their news and their future impact in the AI industry).
To truly understand this paper, I highly recommend reading: The Illustrated Transformer by Jay Alammar. It provides a phenomenal model explanation (including math), inference, and training details. You can also watch this great video breakdown: Attention is all you need (Transformer) - Model explanation.
Objective
Create a model for a sequence-to-sequence task. Given a sequence of data (called tokens), the objective is to predict the next token.
Recurrent Neural Networks (RNN)
Before Transformers, RNNs were the old standard method. However, they were slow and produced poor quality for longer sequences due to the vanishing gradient issue, which made it hard for the network to remember early inputs in long sentences.
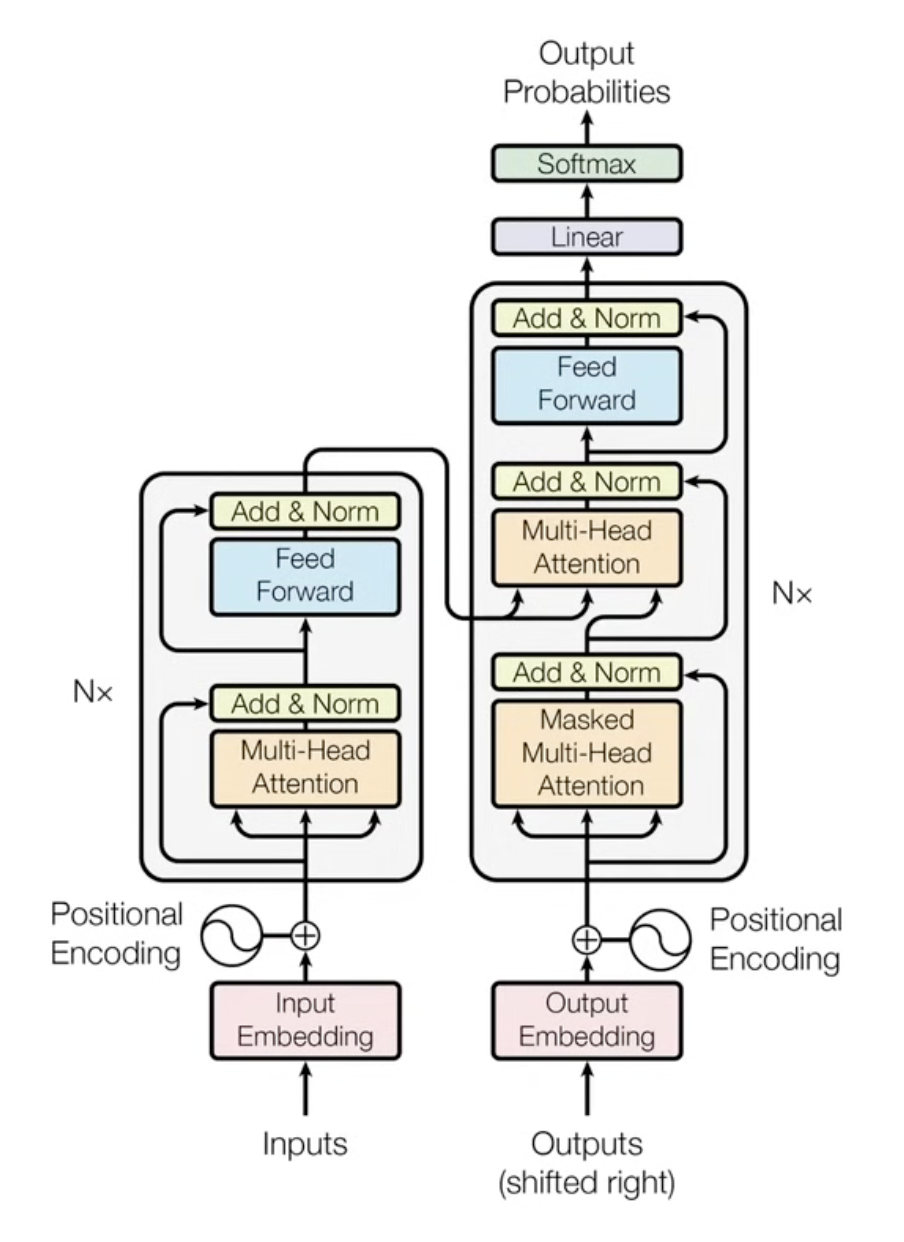
The Transformer Architecture
Transformers solved the limitations of RNNs using an Encoder-Decoder architecture built heavily around matrix multiplications and dot products ($A \cdot B^T$).
Core Components
-
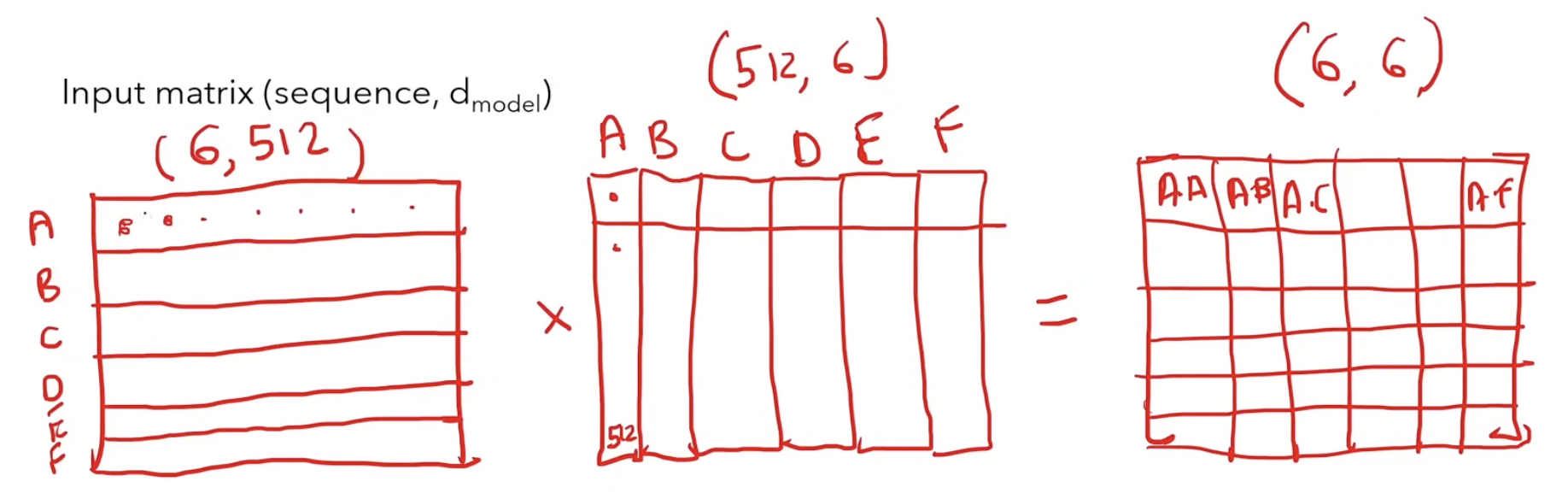
Input Embedding: Converts a raw token into a Token ID, which is then mapped to a 512-dimensional continuous vector (a learnable embedding).
-
Positional Encoding: Since Transformers process all tokens simultaneously (no inherent sequence order), a fixed sin/cos-based function injects position information into the token embedding.
-
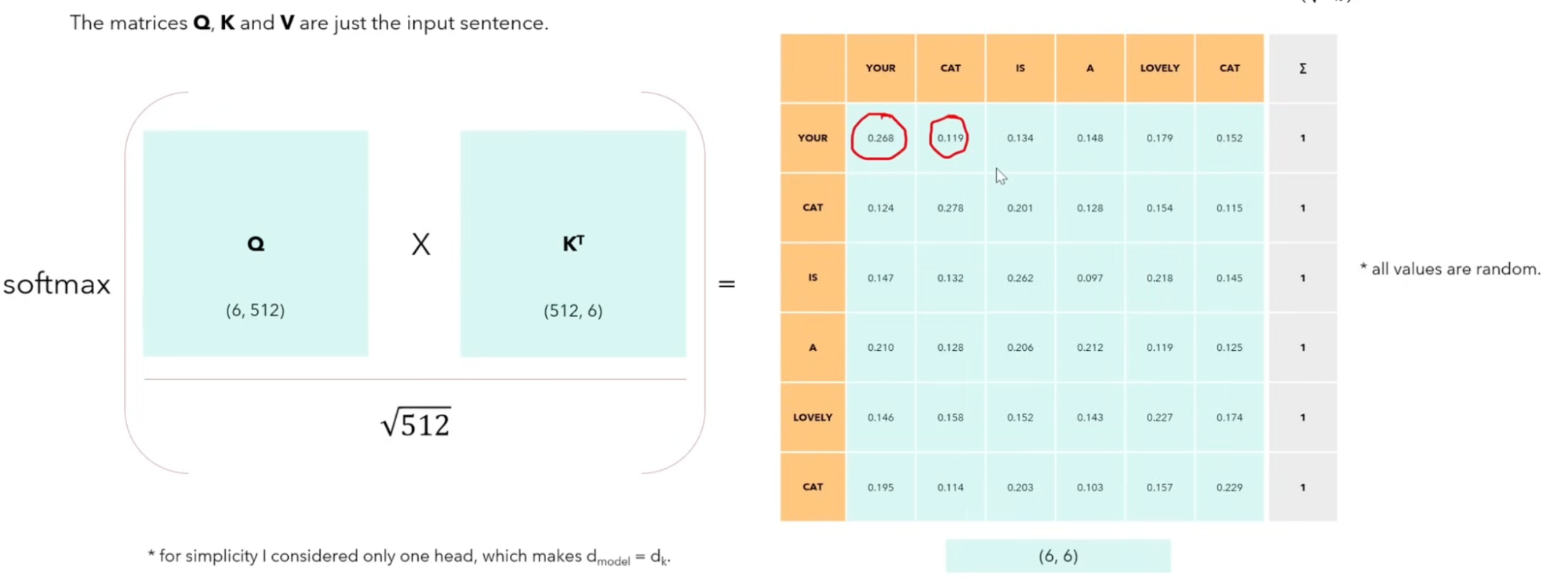
Single-Head Self Attention: Allows the model to relate words to each other within the input sequence. Note: This requires no learnable parameters except for the initial token embeddings.
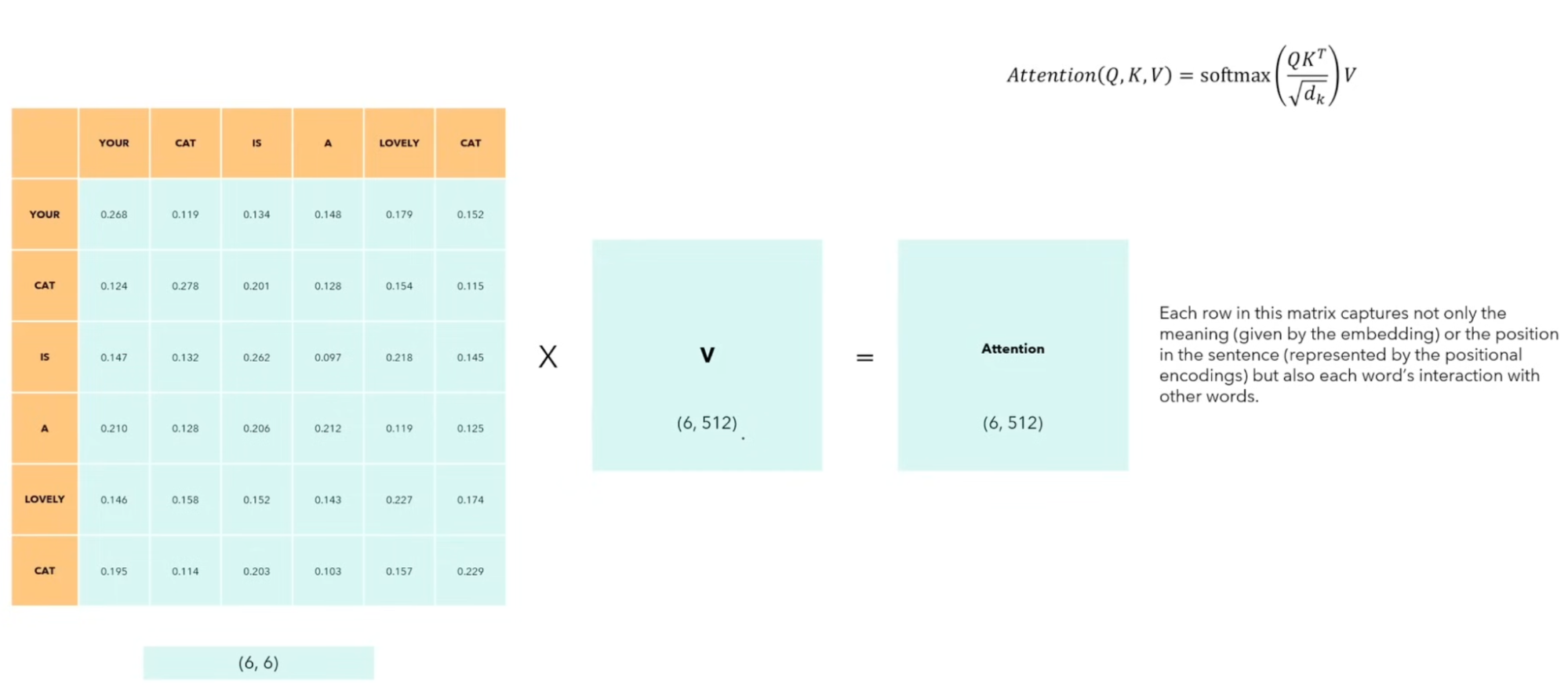
-
Multi-Head Self Attention: Divides the 512-dimensional embedding into multiple parts (heads), calculates attention independently, and then concatenates them. This allows the model to attend to different aspects of the context simultaneously. Learnable Parameters: $W_q, W_k, W_v, W_o$.
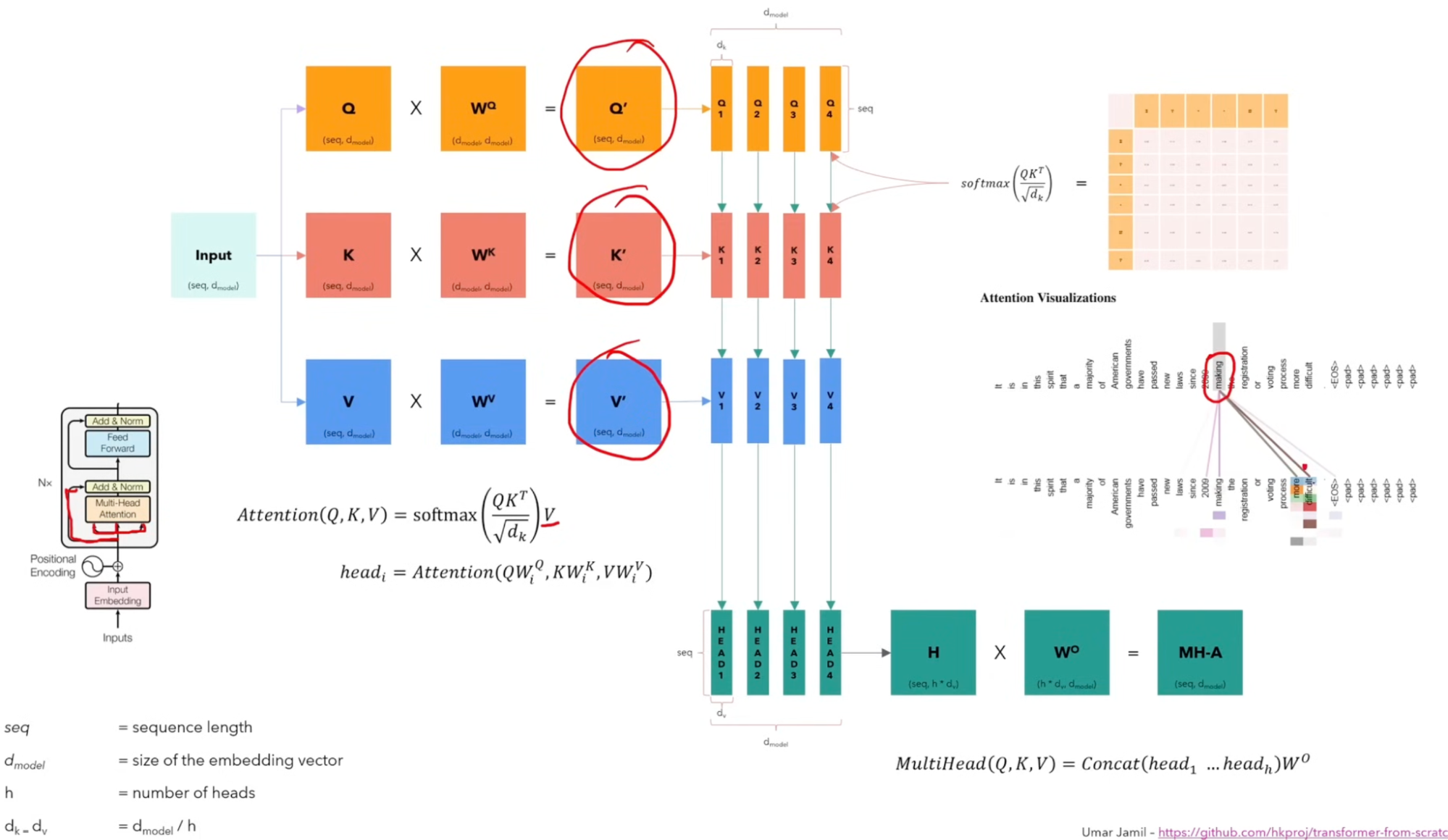
-
Add & Norm: Layer Normalization is applied using the mean ($\mu$) and variance ($\sigma$). It utilizes learnable parameters Alpha (for scaling) and Gamma (for shifting).
-
Masked Multi-Head Attention: Used in the decoder. It masks (makes zero) the upper right triangle of the attention matrix, ensuring the model cannot “look ahead” at future tokens during training.
Training & Inference
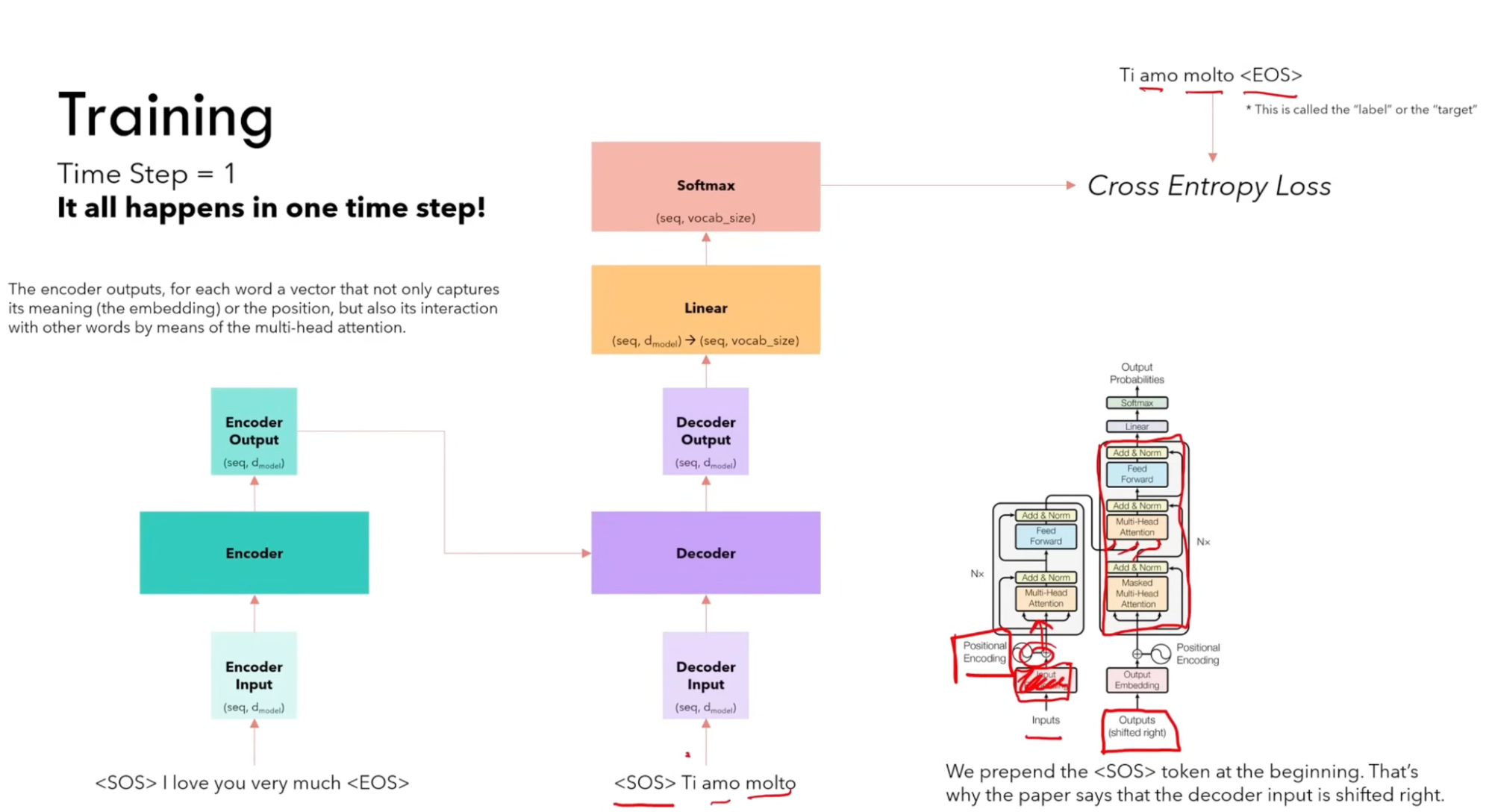
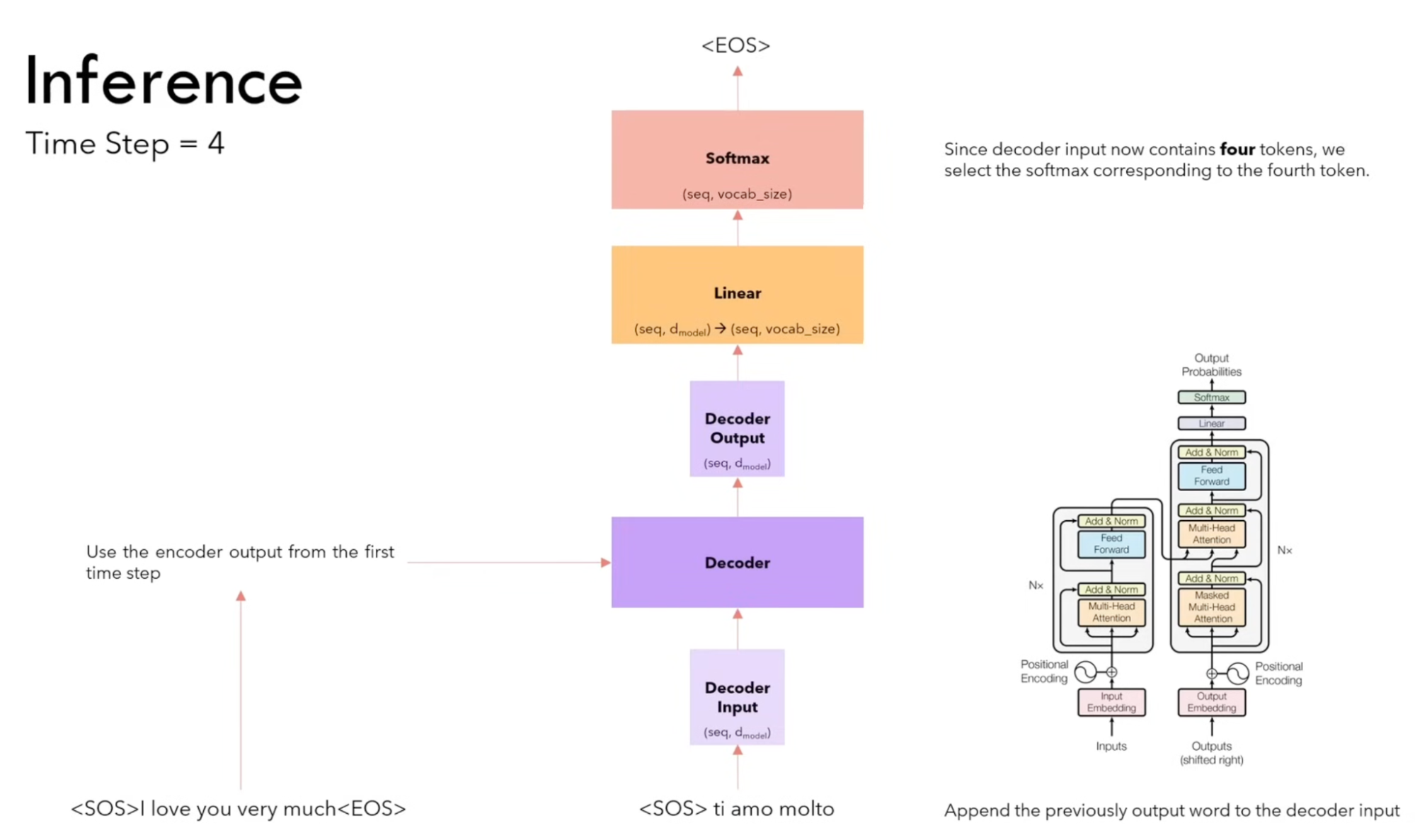
Large Language Models (LLMs)
Modern LLMs (like LLaMA) have evolved from the original Transformer. They typically rely on Next Token Prediction and use a Decoder-only architecture.
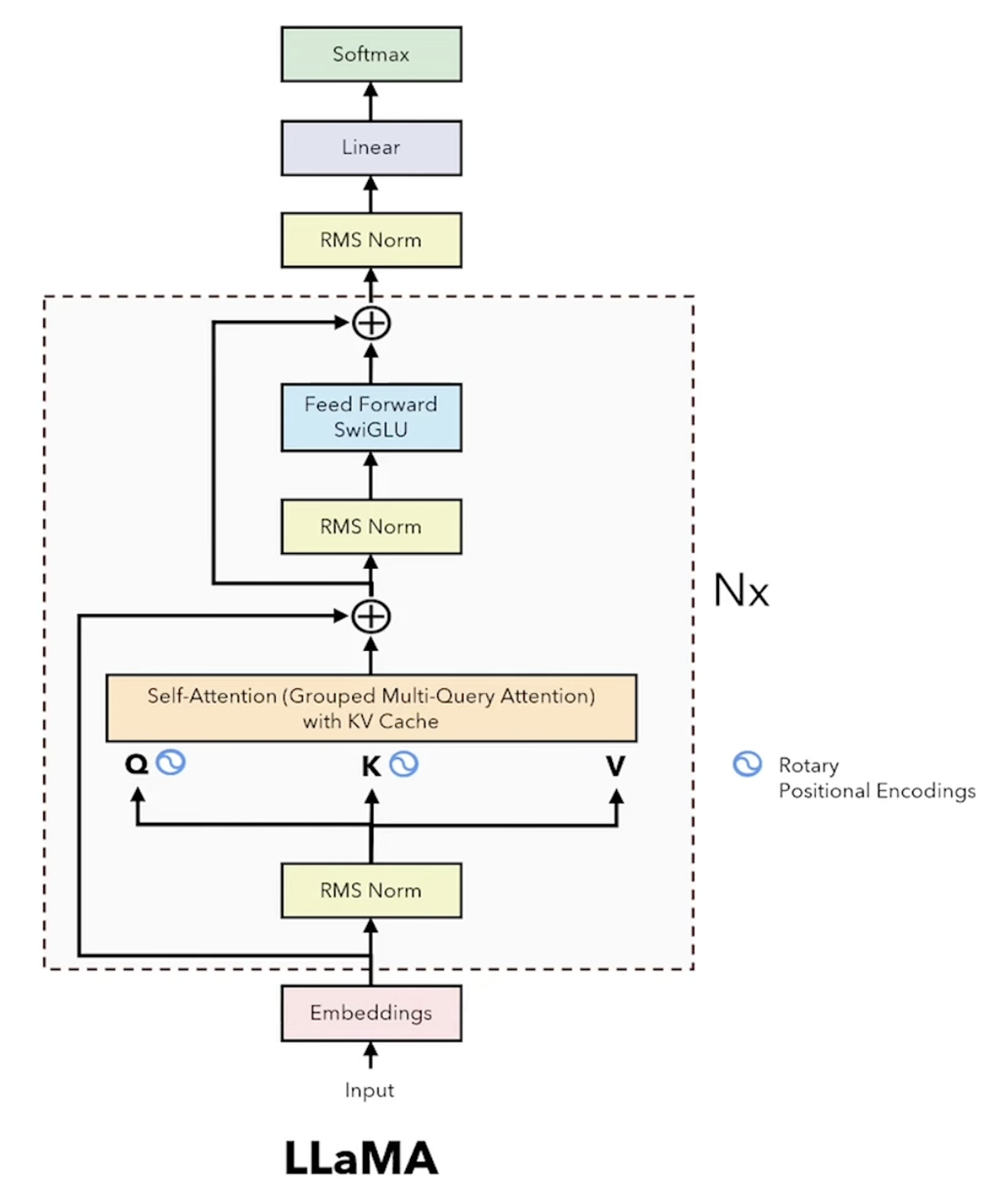
(For a deep dive into how these apply to LLaMA, check out: LLaMA explained: KV-Cache, RoPE, RMS Norm, Grouped Query Attention, SwiGLU)
To make these massive models efficient and effective, several advanced techniques have been introduced:
Key Techniques
- RMS Norm: Root Mean Square Normalization normalizes each token’s activations to prevent covariate shift, making training more stable and computationally cheaper than standard LayerNorm.
- RoPE (Rotary Positional Embedding): Instead of adding positional encodings to embeddings, RoPE rotates the query and key representations at specific angles. This handles long-term decay effectively and generalizes better to longer sequences.

- KV Cache: During inference, instead of recalculating Keys (K) and Values (V) for all previous tokens, the model keeps their computations in memory. It only calculates the Query (Q) for the final predicted token, drastically speeding up generation.
- Grouped Multi-Query Attention: Divides Query embeddings into $n$ heads, but shares a smaller number of heads for Keys and Values. This significantly reduces the size of the KV cache kept in memory during inference.
- Flash Attention: Since AI chips (GPUs) are highly memory-bound, Flash Attention is an algorithm that fuses operations and optimizes memory access (SRAM vs HBM), making attention calculation much faster without losing exactness.
- Longformer: Combines global attention (for specific task tokens) with sliding window attention (local context) to process extremely long documents efficiently without the quadratic cost of standard self-attention.
- Quantization: A technique to reduce the precision of the model’s weights (e.g., from 32-bit floats to 8-bit or 4-bit integers). This shrinks the model’s memory footprint and speeds up inference with minimal loss in quality.
- RLHF (Reinforcement Learning from Human Feedback): A fine-tuning method where human testers rank model outputs. A reward model learns these preferences and uses Reinforcement Learning (typically PPO) to align the LLM’s responses with human values—making it helpful, harmless, and honest.