
“ChatGPT broke the Turing test.”!
The machine learning field is at its epitome as LLMs have unlocked the doors of infinite possibility. This makes me ponder, where exactly are we heading?
- Model sizes — Increasing (M -> LM -> LLM): As large as 70Billion parameter models are becoming the norm.
- Specificity -> Generalisability: Deviating from the earlier norm, models are not trained on particular tasks, but are made to be generic and to mimic human behaviour and knowledge pattern.
- Instruction fine-tuning dataset size — Decreasing: The amount of data needed to fine tune a pre-trained model is decreasing. In fact, the prompts that we are writing to LLMs are an example of the minimal fine-tuned set that we used to direct it.
- Era of Unstructured Reasoning: Models are able to reason out from unstructured instruction and information. The information and instructions provided to the model need not follow a defined format in the case of an LLM.
- Knowledge Evolution: Knowledge increases by sharing and that is what has made humans increasingly knowledgeable. In todays world, this knowledge sharing is getting orchestrated largely by the internet. Imagine the power of something that is trained on the complete internet.
Why is prompt formatting important?
The structuring of the prompt fed to the LLM for achieving any task plays an important role in defining the accuracy and consistency of the results. Even quite small variations in the prompt can lead to highly varied resulting accuracy (https://arxiv.org/pdf/2310.11324.pdf). Some of the common inherent LLM Issues are
- Variability in answer even with temperature 0
- Missing out instruction details if it’s lengthy or complex
- Unable to contain answers in a fixed supported set
The format of the prompt plays an even higher role if it is to be used in a defined pipeline to process high throughput data for the same task. As the task becomes complex, a planning framework needs to be introduced that could break the task into multiple steps and allow for external tool use and knowledge to enhance the results and overcome the inabilities of the LLM. Some common prompting frameworks/techniques have been described below. They can be used as standalone or in combination as well to get better results with the only downside being an increased number of prompt tokens.
Prompt Formats
Some of the common prompt templates are specified below. There is no clear winner when deciding on the prompt format. Based on the task, one can experiment with multiple formats and use the one that works best. Each format is denoted by an acronym and the words specify the part of the use case that has to be described in the sequential order.
APE: Action, Purpose, ExpectationTAG: Task, Action, GoalERA: Expectation, Role, ActionRACE: Role, Action, Context, ExpectationTRACE: Task, Request, Action, Context, ExampleCARE: Context, Action, Result, ExampleRISE: Role, Input, Steps, ExpectationRISEN: Role, Instructions, Steps, End goal, NarrowingROSES: Role, Objective, Scenario, Expected Solution, StepsRODES: Role, Objective, Details, Examples, Sense CheckRTF: Role, Task, FormatCOAST: Context, Objective, Actions, Scenario, TaskCOSTAR: Context, Objective, Style, Tone, Audience, Response Format
Based on a recent context, the winner claimed the COSTAR prompt format to work best. However, this observation would work specifically for a large generative use case that requires the LLM to be creative and write long paragraphs or summaries.
I use the following format as it offers easy modification and there is a clear distinction between the different parts. This has been tested thoroughly and works best in the given order.
- User Message — The user message upon which the instructions are to be performed is specified at the beginning. Since it can be long and might contain instructions that can be confused with the actual instructions, its presence in the beginning ensures that the actual instructions are not getting overridden.
- Task Type — Optional captioning of the task. It helps in grouping the same instruction sets that can be helpful in the construction of a training dataset.
- Steps — A list of steps needed to perform the required task.
- Schema — The format or the JSON schema that the output should adhere to. This is validated after the generation and if there are some inconsistencies then it is re-prompted back to the LLM for its fix.
- Allowed Values — The allowed set of values or excerpts from the knowledge base to ground the output.
- Reminder — A list of reminders that are added along the testing phase to correct any recurring mistakes in the output.
Some of the additional practises that I found to benefit the adherence to instructions are:
- Atomicity of instructions — If an instruction is complex and requires multiple tasks/steps, try to break it into a smaller set of independent atomic instructions, that can run in parallel or sequential manner. Separate calls are made to the LLM for the atomic instructions and compiled together to get the final answer.
- Simplification/ Enhancement of User Message — Sometimes the user message that is to be processed is quite brief/verbose and important parts needed for its evaluation get missed. A preprocessing step (which can be carried out by an LLM) that enhances the user message to only contain the limited information needed for its processing can help in the instruction adherence step.
- Validation and Re-prompting — LLM are often prone to not adhere to the specified output format, especially JSON. Hence the output needs to be validated via external packages like json-schema or pydantic and the mistakes in the output are to be re-fed to the LLM for correction. Techniques like structured generation (https://blog.dottxt.co/coalescence.html) can be used in cases when the output LLM logits are exposed.
- Smaller the instruction, lower the position in the prompt — LLMs work on the next token prediction and are prone to forgetting instructions specified at the very beginning of the prompt. Hence the smaller tokened instructions should be positioned at the end so that it retains the information.
Prompting based on Examples
“Shot” refers to the number of examples of input-output provided to the LLM before using it for the actual task.
Zero-shot
An instruction that works without any example is preferred as there are cases when the LLM falters and gets heavily biased by the specific examples provided. Unless the task and the examples are quite generic, zero-shot should be the preferred approach where no examples are provided at the end of the instructions.
Few-shot / In-Context Learning (ICL)
A few examples at the end of the instructions guide the responses of the model and generally improve the results with an increased number of prompt tokens. The few examples act as a mini-training session and help in the model understand the use of instructions. These are particularly helpful if the instructions are not simple to describe and become a bit complex.
Chain of Thought Techniques
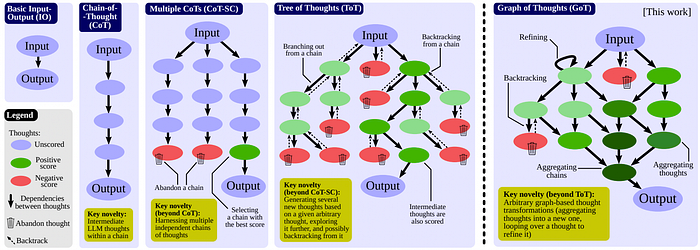
CoT Prompt strategy comparison (https://arxiv.org/pdf/2308.09687)
Chain of Thought (CoT)
Instead of answering the prompt directly, we ask the LLM to break the reasoning process into multiple steps to get to the correct answer. This is generally done in a zero-shot manner by simply adding a phrase like “Let’s work this out in a step-by-step way to be sure we have the right answer” at the end of the prompt. It has proven to respond more accurately. However, since it is thinking in a step-wise manner, it may lead to higher output tokens ultimately leading to higher latency.
Multiple CoTs (CoT-SC)
This approach enhances the result of the simple CoT by evaluating the results of multiple CoTs parallelly. The most consistent answer across the different chains is considered the final answer. It implements a simple measure of self-consistency (SC) and is less prone to errors due to the variability of LLM responses.
Tree of Thought (ToT)
This framework builds on top of CoTs or CoT-SC by modeling the problem as a tree of thoughts. Each branch of the tree represents a possible solution while each node of the branch denotes a partial solution. New branches are created based on existing ones, and then they’re scored. This scoring can be done by a computer or by people. The tree grows based on a plan decided by the search method used, like BFS or DFS. The construction, evaluation, and execution of a tree are done by the use of several agents like a thought generator, state evaluator, and executor. This method is used in applications like BabyAGI.
Graph of Thought
When evaluating the solution to a complex task, people don’t just follow one train of thought (like in CoT) or test separate ones (like in ToT). Instead, they create a complex web of thoughts. They might explore one line of thinking, then backtrack and start another. Later, they might realize ideas from different paths can be combined to create a stronger solution, leveraging their strengths and minimizing weaknesses. Hence consistent with the human-like thought process, a graph of thoughts approach can be leveraged to solve a complex task.
The graph of thoughts is an extension of the ToT the complex problem is decomposed into atomic reasoning and thinking steps. These atomic thoughts are modeled into a graph and executed based on a plan. During the execution step, the knowledge from the earlier processed thoughts is leveraged to enhance the results.
Automated/Cognitive Prompting
These methods require additional computation or generation of data that is used by the LLM to improve its results.
Reflexion
This is a technique that requires the LLM to answer and then reflect on it to improve its later decision-making. It uses verbal reinforcement to help agents learn from prior failings. For a task, a trajectory is decided by the LLM. Based on the outcome of the trajectory, the LLM is made to generate a reflection. Based on the reflection, it opts to choose a new trajectory. This method is effective when making decisions or generating code, whose output is objective and can be reflected on. However, due to multiple iterations of trial-and-error, it tends to result in increased latency and input tokens.
Metacognitive Prompting
A variant of the reflexion, it aims at enhancing the metacognitive abilities of the LLM. A strategy for self-reflection and evaluation is laid down that helps in reasoning and improving the results. There are particularly 5 steps involved in the answer generation:
- Text Interpretation — What do I know?
- Preliminary Judgement (Reflection) — What is my first thought?
- Inference Evaluation (Reflection) — Is my first thought accurate?
- Final Decision and Evaluation (Self-regulation) — How can I justify my decision?
- Confidence Assessment (Self-regulation) — How confident am I about this decision?
Automatic Prompt Engineering (APE)
In this method, we let the prompt be designed by the LLM itself. With a set of input and output examples, prompt generation is treated as an optimization problem. Candidate prompts are generated by the LLM and they are iterated over to find the resulting accuracies for the supplied examples. This enables the LLM to drill down on the best working prompt for the examples. This auto-prompting technique can be used as a feature from the DsPy package (https://paul-bruffett.medium.com/llm-auto-prompt-chaining-60924329833f). This type of prompting has proven to be better than human-engineered prompts in several cases and is particularly useful for non-generative tasks that can be evaluated objectively.
Generated Knowledge Prompting
In this technique, before directly answering the user prompt, a knowledge generation step is included wherein useful knowledge is generated by the LLM and concatenated with the question. LLM is instructed to answer the question based on the knowledge provided. If there are different components to the question then several such pertinent knowledge generation step is conducted and the LLM is instructed to answer based on the integrated knowledge-base. This is a prompting technique that works best to avoid hallucination specifically in case of factual answering. This is because the answering step is separated from the knowledge retrieval step.
Reasoning Frameworks
Reasoning frameworks are required in the case of complex tasks that require task decomposition and assistance of external functions with some level of coordination.
ReAct — Reasoning and Acting

Comparison of 4 prompting methods, (a) Standard, (b) Chain-of-thought (CoT, Reason Only), © Act-only, and (d) ReAct (Reason+Act), solving a HotpotQA (https://arxiv.org/pdf/2210.03629)
It is the most popular as well as a simple reasoning framework. It is based on utilizing the synergy of reasoning and acting. The reasoning part is powered by the LLMs while the acting part utilizes the response of external actions that are feeded back into the prompt as observation.
The following are the components involved in the ReAct planning framework:
- Question: The input from the user
- Thought: A generated thought by the LLM.
- Action: A proposed external action suggested by the LLM.
- Observation: The response of the action.
Based on the observation, the LLM is prompted again to generate a set of thought and action and the loop continues until it gets to the result.
Dynamic replanning: This framework supports dynamic replanning, wherein based on the observation the model is able to replan the path to reach to its answer.
However ReAct suffers from tool failures, action loops, and lengthy prompts. It is used in LangChain’s CSV Agent and BabyAGI’s Execution Agent.
ReWOO — Reasoning WithOut Observation
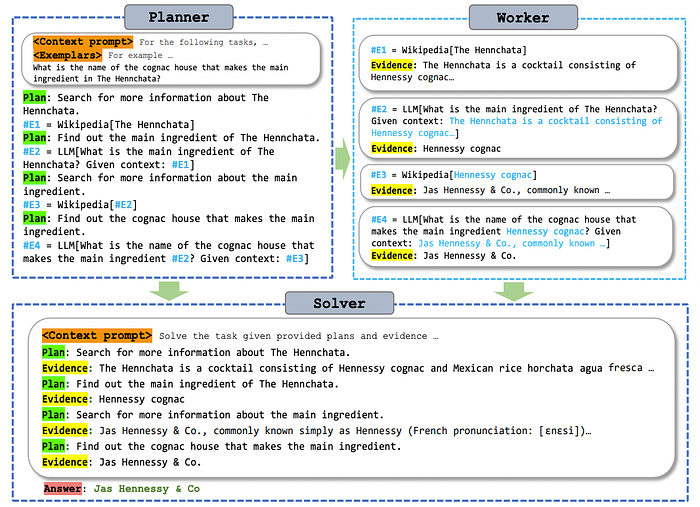
Workflow of ReWOO (https://arxiv.org/pdf/2305.18323)
Observing the issues with ReAct like lengthy prompt and increased time, this work tried to decouple reasoning and observation. This works on the idea of segregating tasks among different experts — Planner, Worker, and Solver.
Planner— The planner lays out the plans and defines the tasks that the worker needs to resolve through external function calls or knowledge retrieval.Worker— Responsible for executing the functional tasks that were decided by the planner.Solver— Aggregates the planning and worker responses and resolves the taskReWOO performs better than ReAct despite not relying on current and previous observations. ReWOO can generate reasonable plans but sometimes has incorrect expectations or wrong conclusions.
Improving the tool responses and the Solver prompt to enhance the reasoning performance is vital to have good ReWOO performance. It is used in AutoGPT/Autogen.
LLMCompiler
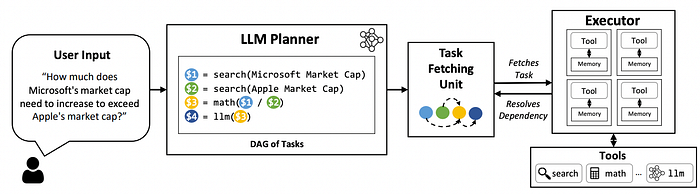
Workflow of LLMCompiler (https://arxiv.org/pdf/2312.04511)
This planning framework makes an attempt to overcome the issues of the ReAct framework while also ensuring Dynamic Replanning and an ability to execute embarrassingly parallel function calling. It consists of three components:
- LLM Planner: Responsible for generating a DAG of tasks with their interdependencies.
- Task Fetching Unit: Responsible for orchestrating task execution, where it dispatches tasks to the Executor by resolving the dependent tasks after replacing their placeholder variables with actual values.
- Executor: Responisible for executing tasks and sending its results back to task fetching unit.
It supports Dynamic Replanning, as after the results of the Planning is resolved, a new DAG can be generated and executed if the answer is unsatisfactory. The framework is particularly helpful in Embarrassingly Parallel Function Calling as the construction of the DAG ensures that the parallel functions are easily identifiable and can be executed concurrently.
Resources:
https://medium.com/@jelkhoury880/some-methodologies-in-prompt-engineering-fa1a0e1a9edb
https://www.mlopsaudits.com/blog/improving-llms-reasoning-in-production-the-structured-approach
https://github.com/SqueezeAILab/LLMCompiler
https://arxiv.org/pdf/2308.09687.pdf